Ngôn ngữ tự nhiên là hệ thống giao tiếp mà con người dùng để diễn đạt suy nghĩ và cảm xúc bằng lời nói hoặc văn bản. Ngôn ngữ tự nhiên phong phú, đa nghĩa và phụ thuộc rất nhiều vào ngữ cảnh, sắc thái và quy tắc ngữ pháp phức tạp. Ví dụ, cùng một câu tiếng Việt có thể hiểu khác nhau tuỳ giọng điệu và hoàn cảnh giao tiếp. Để máy tính “hiểu” được ngôn ngữ này, người ta phải chuyển nó thành dạng mà mô hình học máy có thể xử lý, gọi là xử lý ngôn ngữ tự nhiên (NLP). Công việc của NLP bao gồm chia nhỏ câu thành từ/chữ (tokenization), biểu diễn chúng dưới dạng số (nhúng từ/vectors), và mô hình hoá mối quan hệ ngữ nghĩa giữa các từ. ChatGPT – một ví dụ điển hình của mô hình ngôn ngữ lớn – được thiết kế để giải quyết bài toán này, giúp máy tính sinh ra văn bản tự nhiên trôi chảy dựa trên dữ liệu huấn luyện.

ChatGPT học ngôn ngữ như thế nào?
ChatGPT được tạo ra nhờ huấn luyện trên một khối dữ liệu văn bản khổng lồ. Quá trình này gồm hai giai đoạn chính. Đầu tiên, trong giai đoạn tiền huấn luyện (pre-training), mô hình GPT được cho “đọc” hàng trăm gigabyte văn bản (sách, bài báo, trang web, v.v.) để học các quy luật chung của ngôn ngữ. Mục tiêu ở giai đoạn này là dự đoán từ tiếp theo trong một chuỗi văn bản. Cụ thể, nếu có một câu đang bị bỏ mất một từ cuối, mô hình sẽ cố gắng chọn ra từ phù hợp nhất dựa trên bối cảnh. Bằng cách so sánh dự đoán với từ thật trong dữ liệu, mô hình điều chỉnh các tham số (weights) để cải thiện độ chính xác trong lần huấn luyện kế tiếp. Sau khi tiền huấn luyện, ChatGPT đã hiểu được rất nhiều quy luật ngữ pháp và cách sử dụng từ phổ biến, giống như nền tảng kiến thức chung về ngôn ngữ.
Tiếp theo là giai đoạn tinh chỉnh (fine-tuning) để biến GPT thành ChatGPT có khả năng đối thoại. Công việc này gồm hai bước. Bước 1 là tinh chỉnh có giám sát: các nhà phát triển tạo ra hàng nghìn cặp hội thoại mẫu (prompt – response) do con người viết, rồi cho mô hình học từ những ví dụ này. Bước 2 là học tăng cường từ phản hồi con người (RLHF): ChatGPT tạo ra nhiều câu trả lời khác nhau cho cùng một câu hỏi, sau đó con người xếp hạng các câu trả lời theo mức độ hữu ích. Dữ liệu xếp hạng này được dùng để huấn luyện thêm một “mô hình phần thưởng” (reward model), và cuối cùng ChatGPT được điều chỉnh bằng thuật toán tối ưu hoá (PPO) để tối đa hóa điểm phần thưởng đó. Nhờ vậy, ChatGPT trở nên khéo léo hơn trong giao tiếp giống con người và biết cách ưu tiên các câu trả lời hữu ích.

Mô hình ngôn ngữ lớn hoạt động ra sao?
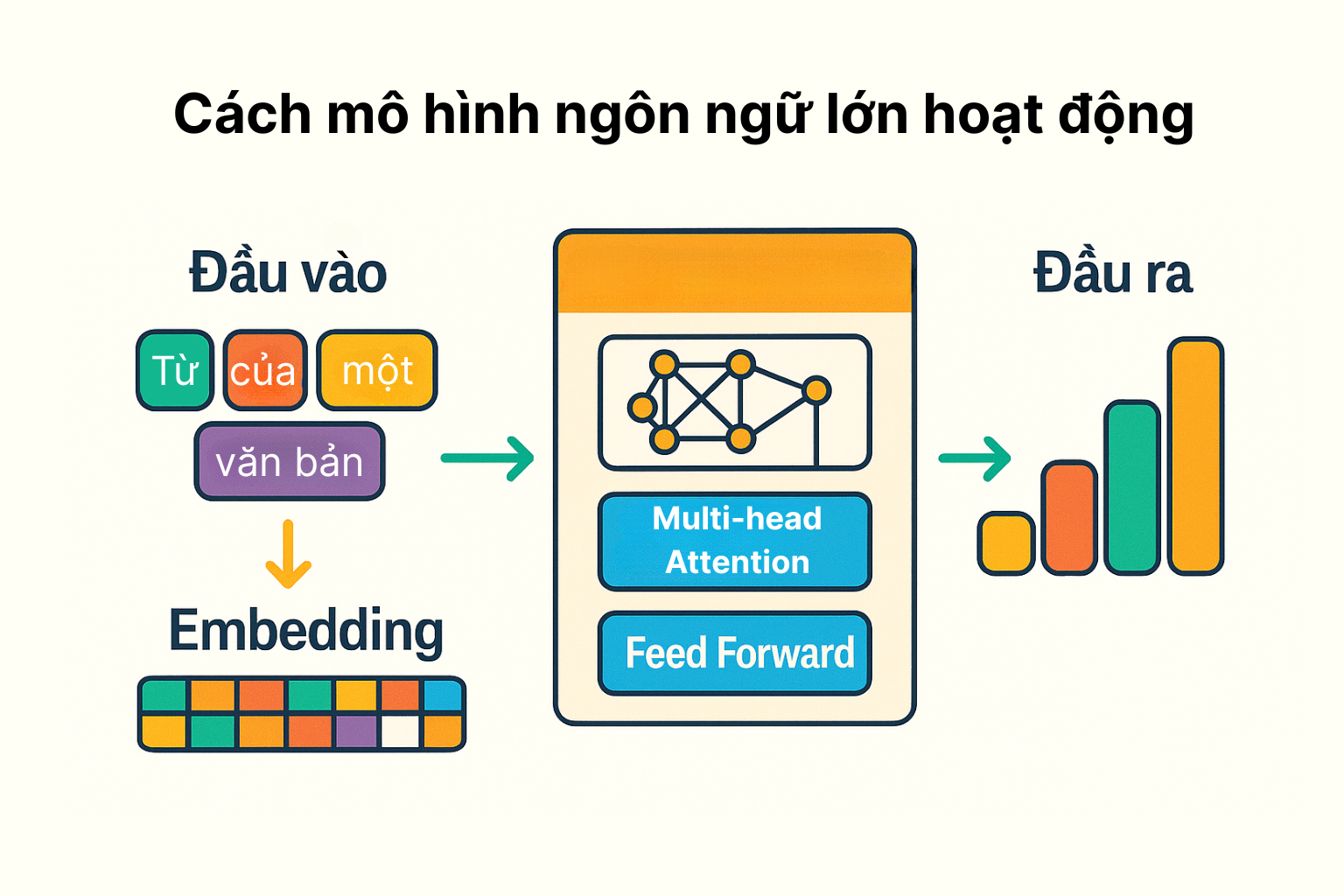
Token hóa và biểu diễn từ (Embedding)
Khi nhận một câu truy vấn, ChatGPT không hiểu trực tiếp các ký tự chữ mà phải chuyển chúng thành dữ liệu số. Đầu tiên, câu văn được phân tách thành các token, có thể là từ, phần từ hoặc ký hiệu. ChatGPT sử dụng thuật toán Byte-Pair Encoding (BPE) để tạo bộ từ vựng khoảng 50.257 token khác nhau. Ví dụ, từ “học” hoặc “học_sinh” có thể được tách thành các token cơ bản (“học”, “_”, “sinh”) nếu cần. Mỗi token sau đó được biểu diễn dưới dạng một vector số học gọi là vector nhúng (word embedding). Các vector này có chiều dài lớn (trong GPT-3 là 12.288) và được học trong quá trình huấn luyện. Vectơ nhúng giúp mã hoá ngữ nghĩa của từ: những từ có nghĩa gần nhau sẽ có vectơ gần nhau trong không gian số học, vì vậy mô hình hiểu được phần nào mối liên hệ giữa chúng.
Khi ChatGPT nhận đầu vào, ví dụ câu “Xin chào, bạn khỏe không?”, nó sẽ token hóa thành dãy token tương ứng. Sau đó, mỗi token được chuyển thành một vectơ nhúng qua ma trận embedding. Đồng thời, ChatGPT thêm thông tin vị trí (positional embedding) để phân biệt thứ tự của các từ trong câu. Sau các bước này, đầu vào được biểu diễn dưới dạng ma trận số, sẵn sàng cho phần xử lý tiếp theo của mô hình.
Cơ chế Attention và Transformer
Khác với các mô hình truyền thống lần lượt xử lý từng từ một (ví dụ RNN), Transformer cho phép xử lý song song toàn bộ chuỗi. Thành phần chủ chốt của Transformer là cơ chế attention. Tóm tắt, cơ chế attention giúp mô hình “tập trung” vào các từ quan trọng trong ngữ cảnh khi tạo kết quả. Ví dụ, khi cần dịch hoặc trả lời câu hỏi, từ đầu vào ở vị trí nào quan trọng đến từ đầu ra ở vị trí hiện tại. Mô hình sẽ học cách gán trọng số chú ý (attention weight) cao cho các từ có liên quan. Nhờ vậy, ChatGPT có thể nắm bắt được mối liên hệ xa xôi giữa những thành phần trong câu. Cụ thể, trong bài báo “Attention Is All You Need” (2017), người ta giới thiệu kiến trúc Transformer, cho phép mạng “chú ý đến các phần khác nhau của đầu vào khi xử lý”. Trong ChatGPT, mỗi lớp của Transformer gồm nhiều “đầu attention” (multi-head) hoạt động song song, kết hợp thông tin từ các vị trí khác nhau của câu để tạo ra đại diện ngữ cảnh tổng thể. Kết quả là, khi ChatGPT sinh văn bản, nó có khả năng kết hợp ngữ nghĩa tổng thể và lấy ví dụ gần giống với cách con người chú ý chọn lọc thông tin.
Dự đoán từ tiếp theo và sinh văn bản
Sau khi tính toán xong các lớp Transformer, ChatGPT tạo một đầu ra dạng phân phối xác suất trên toàn bộ từ vựng. Mỗi token có một xác suất dựa trên biểu diễn ngữ cảnh mà mô hình vừa xử lý. Sau đó, mô hình chọn token có xác suất cao nhất hoặc mẫu ngẫu nhiên (sampling) tuỳ theo cài đặt “nhiệt độ” để sinh từ tiếp theo. Ví dụ, nếu câu đầu vào là “Trời hôm nay…”, ChatGPT có thể đánh giá từ “nắng” có xác suất 0.5, “mưa” 0.3, “u ám” 0.2; nó sẽ ưu tiên chọn “nắng” vì có xác suất cao nhất. Từ được chọn sẽ được nối vào câu, rồi quá trình lặp lại: ChatGPT lại tính toán phân phối cho từ kế tiếp dựa trên câu đã có thêm từ mới. Quá trình này tiếp tục cho đến khi đạt độ dài mong muốn hoặc gặp token kết thúc. Thông qua cơ chế này, ChatGPT có thể sinh ra một đoạn hội thoại dài dòng, tạo nên câu trả lời mạch lạc từ những dự đoán từng từ một. Lưu ý: tham số nhiệt độ (temperature) có thể điều chỉnh mức độ sáng tạo hay ngẫu nhiên của đáp án – nhiệt độ cao thì chọn từ ngẫu nhiên hơn, thấp thì ưu tiên từ có xác suất cao nhất

ChatGPT có thực sự “hiểu” không?
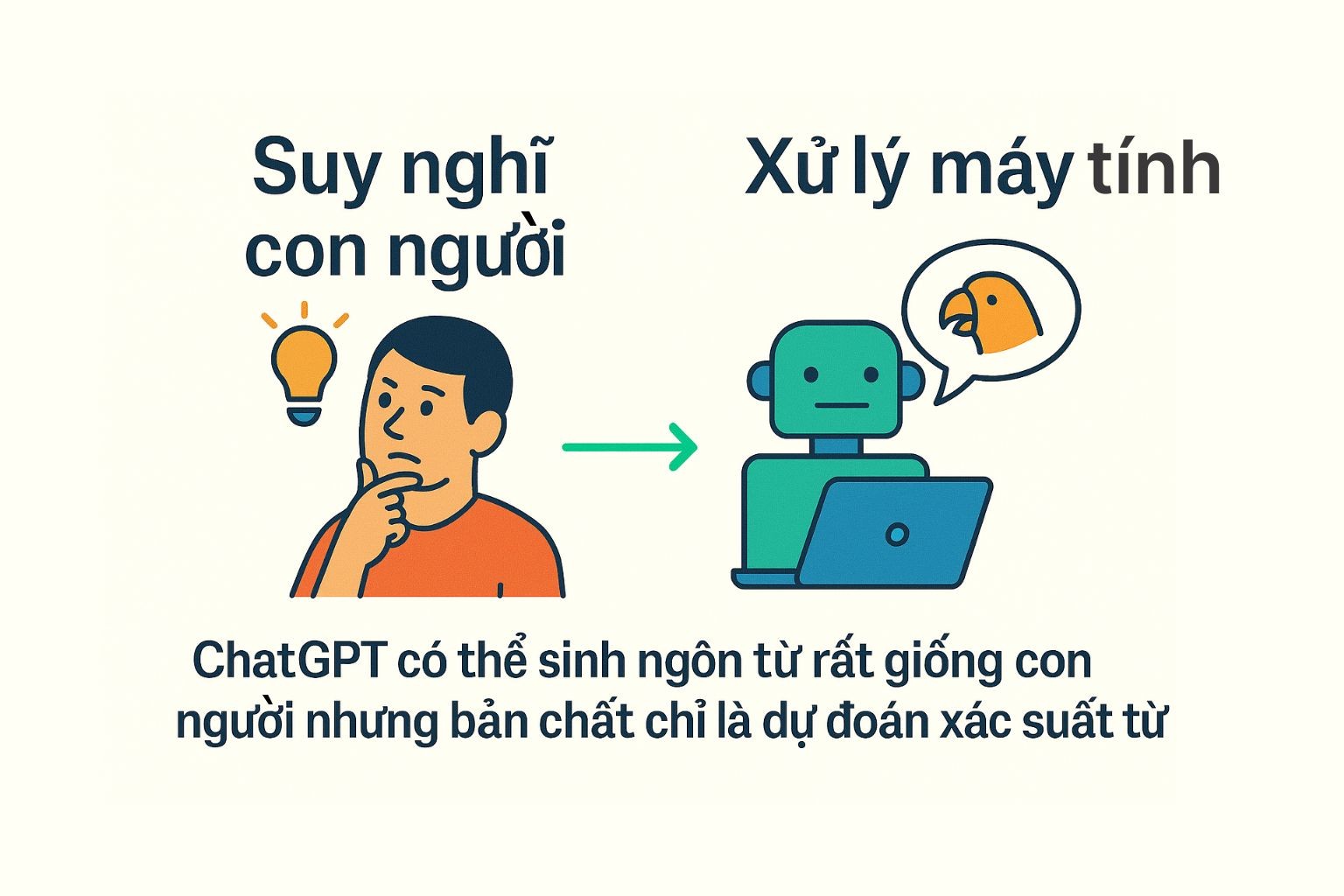
Một câu hỏi lớn là: ChatGPT có thật sự “hiểu” ngôn ngữ như con người? Câu trả lời là: không hoàn toàn. ChatGPT hoạt động theo nguyên tắc thống kê và học máy, không có ý thức hay sự hiểu biết sâu sắc như con người. Mô hình chỉ đơn thuần học các mẫu và quy tắc sử dụng từ trong dữ liệu huấn luyện. Nó có thể nối các từ lại một cách hợp lý và sinh câu trôi chảy, nhưng bản thân nó không có khái niệm về “ý nghĩa” hay “thế giới quan” như con người. Trong cộng đồng nghiên cứu, người ta thường ví ChatGPT giống “con vẹt thống kê” (stochastic parrot): nó có thể nhại lại ngôn từ rất thuyết phục nhưng không thực sự hiểu ngữ nghĩa của những gì nó nói.
Tuy nhiên, cũng có quan điểm khác: một số chuyên gia (ví dụ Ilya Sutskever của OpenAI) cho rằng trong nhiều trường hợp, việc dự đoán từ kế tiếp đòi hỏi mô hình phải “suy luận” dựa trên kiến thức đã học. Chẳng hạn, nếu hỏi tên tội phạm trong một truyện trinh thám, LLM có thể phải nhớ và kết nối nhiều phần của câu chuyện mới đoán đúng. Điều này khiến mô hình có vẻ như “hiểu” hơn là chỉ thuộc lòng. Dù vậy, các mô hình ngôn ngữ vẫn thường mắc các lỗi ngớ ngẩn và đưa ra câu trả lời sai (như “hallucination” – phát hiện thông tin không có thật trong dữ liệu huấn luyện).
Tóm lại, ChatGPT không có hiểu biết nhận thức thật sự; nó chỉ thực hiện rất tốt việc tính toán ngẫu nhiên có điều kiện dựa trên các pattern ngôn ngữ. Nói cách khác, ChatGPT mô phỏng sự hiểu biết thông qua xác suất và thống kê, chứ không có kinh nghiệm hay tư duy như con người. Khi sử dụng ChatGPT, ta nên nhớ rằng nó dựa hoàn toàn vào dữ liệu đã học, nên sẽ thiếu khả năng “suy nghĩ” sáng tạo hoặc cập nhật thông tin mới ngoài dữ liệu huấn luyện.
Kết luận
ChatGPT là một mô hình ngôn ngữ lớn tinh vi, được huấn luyện trên một lượng dữ liệu khổng lồ và dựa trên kiến trúc Transformer hiện đại. Nó “hiểu” ngôn ngữ ở mức độ mô hình hóa thống kê: chia câu thành token, biểu diễn chúng bằng vector, dùng attention để nắm bối cảnh, rồi dự đoán từ tiếp theo theo xác suất. Nhờ vậy, ChatGPT có thể trả lời câu hỏi, viết văn, dịch thuật… rất giống ngôn ngữ tự nhiên của con người. Tuy nhiên, nó chỉ dựa vào các quy luật đã học trong dữ liệu, không có ý thức, kinh nghiệm hay ý nghĩa thực sự đằng sau câu chữ. Trong tương lai, các hướng nghiên cứu mới sẽ cố gắng cải thiện khả năng hiểu biết ngữ nghĩa và giảm thiểu những sai sót (“hallucination”) của mô hình. Độc giả có thể tưởng tượng ChatGPT như một “tập hợp trí nhớ ngôn ngữ” rất mạnh: nó biết rất nhiều nhưng chỉ học hỏi từ dữ liệu, chứ không có khả năng thực sự cảm nhận thế giới như con người.




![[Trải nghiệm] Early Childhood English](https://eduz.vn/datafiles/8/2025-12/thumbs-1767064451-early-childhood-english-sample-16978612137109.png)
![[Trải nghiệm] Tiếng Anh Công Nghệ](https://eduz.vn/datafiles/8/2025-12/thumbs-tieng-anh-cong-nghe-17645814158532.jpg)








![[DN5SAO] Tập Huấn Sinh Viên Thực Tập](https://eduz.vn/datafiles/8/2024-06/thumbs-chuong-trinh-tap-huan-17192904622640.png)

.png)


![[Pre-Ket] English Bridging Course](https://eduz.vn/datafiles/8/2023-12/thumbs-tieng-anh-pre-ket-17016625402127.png)

![[Trải nghiệm] Lớp học Mầm non](https://eduz.vn/datafiles/8/2023-11/thumbs-Xuong-sang-tao-16995224364239.png)
![[IE01] IELTS Foundation](https://eduz.vn/datafiles/8/2023-10/thumbs-IELTS-Foundation-16983332898951.jpg)

![[EP04] Starters Special Englsh](https://eduz.vn/datafiles/8/2023-10/thumbs-ep04-starters-special-englih-16978616146081.png)

![[EP03] Pre-Starters English](https://eduz.vn/datafiles/8/2023-06/thumbs-LOP-TIENG-ANH-NEN-TANG-EP03-1-16877523348263.png)
![[SP03] Flyers Special English](https://eduz.vn/datafiles/8/2023-10/thumbs-10-16978616717569.png)
![[Trải nghiệm] Early Childhood English](https://eduz.vn/datafiles/8/2023-10/thumbs-early-childhood-english-sample-16978612137109.png)
![[Trải nghiệm] Flyers Special English](https://eduz.vn/datafiles/8/2023-10/thumbs-flyers-special-english-sample-16978611197822.png)
![[Trải nghiệm] IELTS Foundation](https://eduz.vn/datafiles/8/2023-06/thumbs-FOUNDATION-16820880185427.png)
![[Trải nghiệm] Starters Special English](https://eduz.vn/datafiles/8/2023-10/thumbs-Starters-special-english-sample-16978609846972.png)
![[Trải nghiệm] Foundation English](https://eduz.vn/datafiles/8/2023-10/thumbs-foundation-english-sample-16978611717701.png)
![[Trải nghiệm] Vẽ Màu nước Mầm Non](https://eduz.vn/datafiles/8/2023-10/thumbs-ve-mam-non-16978613446713.png)

![[Trải nghiệm] Lập trình Sáng tạo (Scratch JR)](https://eduz.vn/datafiles/8/2023-06/thumbs-MON-HOC-2022-1-png-16572787941934.png)














![[Trải nghiệm] Movers Special English](https://eduz.vn/datafiles/8/2023-10/thumbs-Movers-special-english-sample-16978610829297.png)



![[EP02] Foundation English](https://eduz.vn/datafiles/8/2023-03/thumbs-Asset-32x-16781852553762.png)
![[Trải nghiệm] Doodle - Nguệch ngoạc vẽ thế giới](https://eduz.vn/datafiles/8/2023-10/thumbs-doodle-nguech-ngoac-ve-ca-tg-16978612718892.png)




![[SP02] Movers Special English](https://eduz.vn/datafiles/8/2023-10/thumbs-movers-special-english-16978616885043.png)






![[SP01] Starters Special Englsh](https://eduz.vn/datafiles/8/2023-10/thumbs-sp01-starters-special-english-16978615673911.png)





![[EP01] Early Childhood English](https://eduz.vn/datafiles/8/2023-10/thumbs-ep01-early-childhood-english-16978614739394.png)